 Geschichte von Hadoop:
Geschichte von Hadoop:
Hadoop wurde vom Leunce-Erfinder Dough Cutting initiiert und 2006 erstmals veröffentlicht. Am 23. Januar 2008 wurde es zum Top-Level-Projekt der Apache Software Fundation.
Nutzer sind unter anderem Facebook,Yahoo, IBM. Dough Cutting entwickelte zuerst Nutch. Hadoop wurd von Nutch abgeleitet.
Nutch:
Nutch ist ein Java-Framework für Internet-Suchmachine. Die Software ist Open-Source und wird innerhalb der Apache Software Fundation unter der Apache-Lizenz entwickelt. Nutch basiert u. a. auf Lucence (Stemming, Indexierung etc.), Solr (Webfunktionalitäten) und Hadoop(Skalierung). Nutch wird zur Zeit in 2 Versionen gepflegt:
- 1.x: Ist ein fertiger Crawler, welcher eine sehr feine Konfiguration ermöglicht und auf die Datenstrukturen von Apache Hadoop setzt, er soll ideal für Batch-Verarbeitung sein.
- 2.x: Wird als Alternative zur Version 1.x angeboten, der
Hauptunterschied liegt im Speicherbereich, dieser wurde abstrahiert und
nutzt Apache Gora um Objekte zu verknüpfen. So wurde die Flexibilität
erhöht, was (z. B. Status, Inhalte, Links, verarbeiteter Text …)
gespeichert werden kann und wie die Speicherung z. B. in NoSQL-Lösungen
erfolgt.
Ein Hadoop–Cluster ist
ein Zusammenschluss von Servern zu einem Computer-Cluster, was die
Speicherung und Analyse von enormen Datenmengen ermöglicht. Durch die
verteilte Rechenleistung wird besonders rechenintensive
Datenverarbeitung möglich. Hadoop ist eine kostenlose Software.
- Stärken
- Sehr große Dateien: Hunderte TB
- Skaliert auf tausende Standard-Server
- Automatische Verteilung und Replikation
- Ausfallsicher: Fehler sind Regel
- Schwächen
- Physische Lokationen von Blöcken intransparent
- eingeschränktes Optimierungspotenzial für höhere Dienste (wie Hive etc.)
Hadoop ermöglicht Verwaltung und Verarbeitung der Daten mit niedrigen Latenzzeiten.
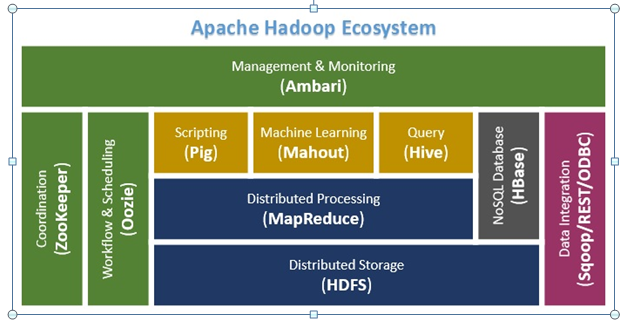
Hadoop Architektur:
HDFS – Hadoop Distributed File System
Das Herzstück von Hadoop ist das verteilte Dateisystem Hadoop Distributed File System (HDFS). HDFS
ist ein hochverfügbares, verteiltes Dateisystem zur Speicherung von
sehr großen Datenmengen, welches in Clustern von Servern organisiert
ist. Dabei werden die Daten auf mehreren Rechnern (Nodes) innerhalb
eines Clusters abgespeichert, das passiert in dem die Dateien in
Datenblöcken mit fester Länge zerlegt und redundant auf den Knoten
verteilt.
MapReduce:
Bei MapReduce handelt es sich um ein von Google entwickeltes Verfahren,
mit dem sich große strukturierte oder unstrukturierte Datenmengen mit
hoher Geschwindigkeit verarbeiten lassen. MapReduce nutzt die
Parallelisierung von Aufgaben und deren Verteilung auf mehrere Systeme.Ursprüngliche wurde das MapReduce-Verfahren 2004 von Google für die
Indexierung von Webseiten entwickelt. MapReduce ist patentiert und kann
als Framework für Datenbanken verwendet werden. Das Framework eignet
sich sehr gut für die Verarbeitung von großen Datenmengen (bis zu
mehreren Petabytes), wie sie im Big-Data-Umfeld auftreten.
Quelle:
https://www.bigdata-insider.de/was-ist-mapreduce-a-624936/
https://datasolut.com/apache-hadoop-einfuehrung/
https://de.wikipedia.org/wiki/Nutch
https://de.wikipedia.org/wiki/Apache_Hadoop